So much has been written
about indexes that you practically need an index to keep track of things.
Performance is the number one reason why indexes are needed. However, there are
situations where indexes are not needed, so how do you know when and where to
index? To index or not to index, that is the question. Of the many types
available in Oracle, your most common index is going to be those known as
NORMAL. Okay, what does normal mean, and if an index is not normal, then what is
it? Abnormal?
Gavin Powell’s Oracle Performance Tuning for
10gR2 book contains a very good “been there, done that”
explanation of B-tree indexes. The book complements Oracle documentation (Concepts
guide) which lists six
advantages related to using B-tree indexes:
1.
All leaf blocks of the tree are
at the same depth, so retrieval of any record from anywhere in the index takes
approximately the same amount of time.
2.
B-tree indexes automatically stay
balanced.
3.
All blocks of the B-tree are
three-quarters full on the average.
4.
B-trees provide excellent
retrieval performance for a wide range of queries, including exact match and
range searches.
5.
Inserts, updates, and deletes are
efficient, maintaining key order for fast retrieval.
6.
B-tree performance is good for
both small and large tables and does not degrade as the size of a table grows.

So, for a good, all-around
general purpose index, the B-tree index is a safe bet. Of course, there are
many other index types at your disposal, and in general, their use is for
specific cases. For now, let’s look at a simple B-tree indexed table.
Example tables
Given a table with multiple rows
and that a column of interest has null and non-null entries, and if using a
B-tree index, are the records with null values indexed? If the column is
indexed with a unique index, and given that nulls are unique unto themselves,
are the rows with null entries indexed?
Let’s create a test table
and see what the index looks like.
create table index_btree (id number);
create index idx_btree_id on index_btree(id);
insert into index_btree values (1);
insert into index_btree values (null);
insert into index_btree values (2);
insert into index_btree values (null);
insert into index_btree values (3);
insert into index_btree values (null);
insert into index_btree values (4);
insert into index_btree values (null);
insert into index_btree values (5);
insert into index_btree values (null);
Below is a simple query and
the output to report on a table’s indexes (or indices).

Ten rows were inserted, and
the results show the five distinct keys. Now let’s create a similar table with
a unique index (and use a slightly different query).

The table with the unique
index still only shows five distinct keys, and the index type is normal, so two
conclusions can be drawn. The first is that even with a unique index, the index
type is normal, and that the second is that nulls do not earn an entry into
what we were perhaps hoping to see (ten distinct keys). The index types in a
typical installation are shown below, but the Reference
guide only lists five of them.
1.
IOT – TOP
2.
LOB
3.
FUNCTION-BASED NORMAL
4.
FUNCTION-BASED DOMAIN
5.
BITMAP
6.
NORMAL
7.
CLUSTER
8.
DOMAIN
In addition to the “normal”
B-tree index and the unique index (also of type normal), what is another normal
index commonly seen? A reverse key index is also normal. Coming back to the original
questions, are nulls ever indexed? The answer is yes, and nulls are indexed
with bitmap indexes. Let’s drop the current index, create a bitmap index, and
query the data dictionary as before:

Note that the index type now
reflects BITMAP and the number of distinct keys has changed to six (the
original values of 1-5, plus an incremental increase of one for the five
nulls). Although nulls are not equal to other nulls, a bitmap index considers
them to be just the opposite, that is, the five null values are considered to
be one distinct value.
Use the right type of index
There are also fairly
specific situations where certain types of indexes should never be used. One of
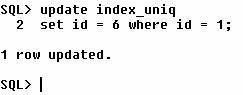
those situations concerns using a bitmap index on an OLTP database. Creating a hot
block is easy to do. Perform an update on a bitmapped index table in one
session and then try an update in another session. It may be quite likely the
block in question will include other records. The other session will be blocked
(indefinitely) until the first session commits or rolls back. In the figure
below, the top left session has updated a table. The session in the top right
is blocked, and a query using V$SESSION (at the bottom) reflects the blocked
session’s status.
|
|
|
|
|
|
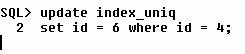

Again, one of the advantages
of using a B-tree index is that exact matches can be retrieved. Using the same
table, but with a normal B-tree index back in place, both sessions can update
at the same time.
|
|
|


Rules to live by
We know why we want to index
a table, so having a short list of rules or guidelines is useful in helping us
figure out how and what, and what to avoid. Powell’s book list four, and they
are:
- Use as few columns as possible
-
Only index integers if possible,
preferable unique integer identifier values -
Use variations on the simple
B-tree index (reverse key, compression, and function-based) when the situation
permits - Null values are not indexed
Two other key rules are:
-
Index columns used as foreign key
references -
Don’t use bitmap indexes on
OLTP-type databases (or in databases where a lot of DML occurs)
Whatever you do with
indexes, be sure to name them with some consistency. A common convention is
<table name>_<column>_<type of index>. Oracle uses such a
scheme in the sample schemas. The EMPLOYEES table in the HR sample schema
(assuming no alterations after the initial setup) has six indexes. The names
are:
- EMP_NAME_IX
- EMP_MANAGER_IX
- EMP_JOB_IX
- EMP_DEPARTMENT_IX
- EMP_EMP_ID_PK
- EMP_EMAIL_UK
By examining the names, you
can tell (for the most part) what the indexes are related to. In this example,
we can generally assume four of the indexes are for the name, manager, job and
department columns. The primary key column (EMP_ID) is easy to identify. The
EMAIL column has a unique index as well. We can use the same query from the
previous examples to obtain index information for a table.
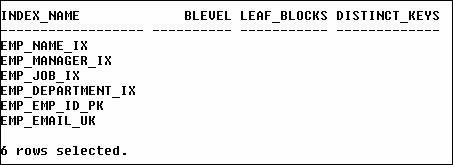
Why isn’t there any
information about these indexes? Here are the descriptions of each column (as
found in the reference guide):
BLEVEL*
B*-Tree level: depth of
the index from its root block to its leaf blocks. A depth of 0 indicates that
the root block and leaf block are the same.
LEAF_BLOCKS*
Number of leaf blocks in
the index
DISTINCT_KEYS*
Number of distinct
indexed values. For indexes that enforce UNIQUE and PRIMARY KEY constraints,
this value is the same as the number of rows in the table
(USER_TABLES.NUM_ROWS)
Upon further inspection,
note the asterisks by each column’s name. The significance of the asterisk is
spelled out in a note.
Note:
Column names followed by an asterisk are populated only if you
collect statistics on the index using the ANALYZE
statement or the DBMS_STATS
package.
For whatever reason, the
EMPLOYEES table seems to have lost its statistics. We can use DBMS_STATS to
gather (and delete) statistics. After collecting statistics, the results of the
query are much better.

In Closing
Indexes are extremely useful
and a little knowledge can go a long way towards making a database perform
well, or at least better. Where to get that knowledge may seem to be the
hardest part in all of this, but Gavin Powell’s book definitely facilitates
acquiring knowledge essential for being an effective DBA.