Table partitions in Oracle can be extremely useful and becoming proficient in managing them doesn’t take too long to accomplish. The benefits of using partitions (and you should realize them since you must pay extra for this feature) are listed in various places, but the short and sweet of it is shown below:
- Faster Performance—Lowers query times from minutes to seconds
- Increases Availability—24 by 7 access to critical information
- Improves Manageability—Manage smaller ‘chunks’ of data
- Enables Information Lifecycle Management—Cost-efficient use of storage
Just how much extra do you have to pay for partitioning? That depends on where you start from. Partitioning is available only with the Enterprise Edition, so if you’re starting from a lower level edition, you’ll have to factor in the edition differential. Even if you’re already starting at the EE level, your cost is around $5,000 for the named user option, but more than likely, $10,000 for the processor option.
This article isn’t directly about the cost of partitioning. Cost is mentioned because if you’re going to pay extra for this feature, there are some partition pitfalls you should avoid, and knowing what they are ahead of time (and even if you’re already using partitioning) can help prevent hours of down time. Down time is another type of cost you may not be able to afford.
Partitioning option by Oracle version
Partitioning seems like something Oracle should have been able to do since day one, but interestingly enough, Oracle8 was its introduction.
|
Oracle Version |
Feature |
|
8 |
Range |
|
8i |
Hash and Composite Range-Hash |
|
9i |
List |
|
10g |
Enhanced features, fast split, IOT, indexes |
Partition operations were admittedly difficult (an iLearning video even says so) in earlier versions, and this difficulty – especially in maintenance operations – made many users leery of implementing this feature.
Table partition options are straightforward, and five of them are: range, list, hash, composite range-hash, and composite range-list. Options for index-organized tables include range, list and hash. Partitioned indexes don’t seem to get nearly as much attention as partitioned tables, and a lack of understanding how the index options differ can lead to significant pitfalls.
Partitioned Indexes
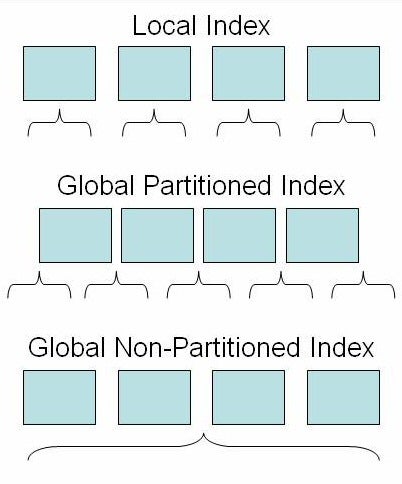
You have three choices when it comes to indexes: local, global partitioned, and global non-partitioned. A local index maps one-to-one with the partitions of the table. A global partitioned index can be based on a different key and even have a different number of partitions. A global non-partitioned index is essentially one big index on the partitioned table. The diagram below illustrates the differences (table partitions are the shaded boxes, indexes are the curly braces).
Problem areas
Where do the pitfalls arise? Two seemingly simple operations can blow away an index and leave your partitioned table in a state of disrepair. There won’t be any data loss, but if an application is dependent on having an index, the loss of that index can bring a session to its knees, that is, what was a .01 seconds lookup can now take 40 minutes. On an OLTP-type database, you’re dead in the water.
The global non-partitioned (GNP) index is the index of interest for the pitfall examples. Think of the GNP index as a map of data, and you should, because that is exactly what it is. What happens when a hole is punched in the middle of the map? In this case, index “data” is lost, so without knowing the complete structure of the index, Oracle declares the index to be unusable, and there goes your performance out the window. From personal experience, rebuilding a 250 million plus records index took almost six hours. A partition, and a very small one at that, needed to be repopulated with data, and there were two choices to clean out the questionable data: simply delete and commit, or truncate the partition. The global index contained the index for the primary key, and the operation to clear the data blew the index, so to speak.
Truncate a partition
How do you truncate a table partition? Does “truncate table X partition Y” work? Actually, the syntax involves “alter table truncate partition.” The key part of the alter table statement is to include two or three words (depending on the type of table and index), and those words are “update <global> indexes.”
Buried in the Administrator’s Guide, applying what is stated in the sentence below means the difference between something routine and something potentially expensive (loss of up time, failure to meet an SLA, slow down on a production line, and so on).
Unless you specify
UPDATEINDEXES, any global indexes are markedUNUSABLEand must be rebuilt.
Personally, I think this statement should be highlighted much better than it currently is, or placed in an indented note or warning/caution statement.
How can you wind up in a situation where a global non-partitioned index is related to a partitioned table? Actually, it is quite easy to create this situation. Partition a table by one key or value, and then create an index on another attribute. An example would be a partition key based on a list (states, departments, subassemblies, etc.) and then base the primary key on, say, a part number. Recall that when creating a primary key (and what other constraint?) you get an index for free. You now have a global non-partitioned index on a partitioned table.
Splitting a partition
The same blown index problem can occur when splitting a partition. At least here, the documentation does a better job of pointing out what happens and how you can prevent it from occurring in the first place.

This example splits a partition (what type of partitioning is being used here?) and keeps global indexes intact.
alter table coupons
split partition p4_coupons values ('415')
into (partition p415, partition p4_coupons)
update global indexes;
Adding “update global indexes” to either operation (truncation and splitting) makes all the difference in the world.
Breaking an index
How do you know what type of index is being used? If you’re using TOAD, a partitioned index sticks out because of an icon. If you’re in SQL*Plus, then you have to be a bit more clever to determine the partition type. Let’s take a look at the SH sample schema via TOAD. Shown below are the indexes for the SALES table.
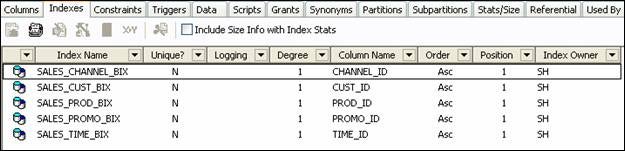
The data is eligible to be contained in 28 partitions, and the partition key is TIME_ID. Not all partitions have records in them, and we’re going to create that situation in one other partition by truncating it. To help illustrate the global non-partitioned index example, we’ll create a pseudo primary key based on a sequence, and then take another look at the indexes.

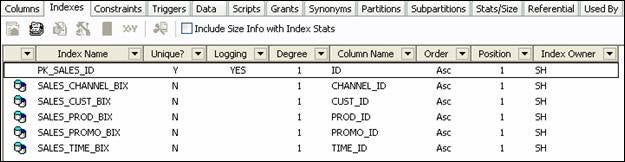
Refresh the list of indexes in TOAD and now the free index named PK_SALES_ID appears.
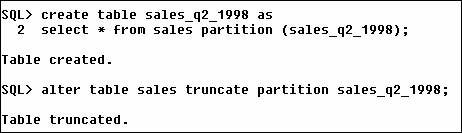
Let’s pick SALES_Q2_1998 as the guinea pig. You can copy the data off into a backup table first if you want to have the SH schema intact afterwards. The picture below shows both steps – copying the data and truncating the partition.
Now that the partition named SALES_Q2_1998 has been truncated, what is the state of our indexes? Refresh the list of indexes in TOAD to see the result.
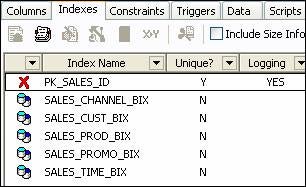
Red X’s in TOAD are symbols you generally do not want to see, as they represent something that is broken or invalid. To fix the index, we have to rebuild it. We can do that through TOAD or via the command line (and TOAD will show you the SQL syntax if so desired).
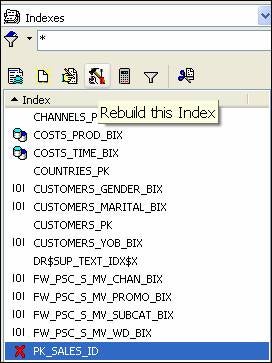
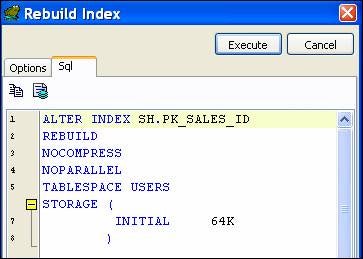
Again, refresh the list of indexes in TOAD and the PK_SALES_ID index is now in a good state. Let’s truncate another partition, but this time add the update indexes clause. But first, just for grins, what happens if we truncate an empty partition and do not use the update indexes clause? Hopefully nothing happens as no index information (because of its associated data) was lost, and you can test the veracity of that statement for yourself.
SQL> create table sales_q3_1998 as 2 select * from sales partition (sales_q3_1998); Table created. SQL> alter table sales truncate partition sales_q3_1998 2 update global indexes; Table truncated. SQL> select object_name from user_objects 2 where status = 'INVALID' 3 and object_type = 'INDEX'; no rows selected
The results indicate that the partition was truncated and that no indexes were marked as unusable (or have a status of INVALID). The same types of examples using a SPLIT operation are easily demonstrated using the same procedures as what we did for the truncate partition operation.
In Closing
The time to rebuild the PK_SALES_ID index is around a minute, and that is for about a million rows. Perhaps a million rows per minute is a rough estimate of how fast an index can be rebuilt (of course your mileage may vary). Extrapolating that rate to the 250 million count table, the time estimate/rate of more than four hours isn’t too far off, and what it does do is point out the fact that it may take hours and hours to rebuild an index. If you can afford the down time for the rebuild operation, you’re fortunate, but what happens when it is a live production system that is crippled for several hours? Hopefully, the point of this article – using the update indexes clause – will help you avoid being caught in that type of predicament.